

Using AWS Resource Groups as a container for your Serverless workflow
Many customers are choosing serverless computing as their approach to solve complex engineering challenges. AWS provides multiple resources that customers can use for their benefits: AWS Lambda as a computing power of the solution, Amazon S3 as highly available storage, or Amazon DynamoDB as a scalable fully managed database service. Many workflows require to handle an asynchronous batch processing of the resources. It can be an audit task that we want to schedule later or heavy processing. It is always worth to invest time into the automation of these tasks. This is where AWS Resource Groups can help you.
This service helps you to organize your AWS resources into one dedicated group. The resource group is a collection of AWS resources that are all in the same region and defined by a search query. This query can be Tag- or AWS Cloudformation stack-based. AWS Resource Groups provide you a reliable source of information about the resources in your groups and can be integrated with you serverless architecture. You can learn more about how to use AWS Resource Groups in your day-to-day operations in this article. In this example, we will take a look into Tag-based resource groups.
Prerequisites
This guide assumes that you have one or more S3 buckets that you will tag. You have two or more Lambda functions that have permissions to interact with these S3 buckets. Additionally, you have installed and updated AWS CLI.
Problem
Let say that you want to build a system that dynamically uploads artifacts to S3 buckets and later process them as a scheduled task. Your design might look like this:
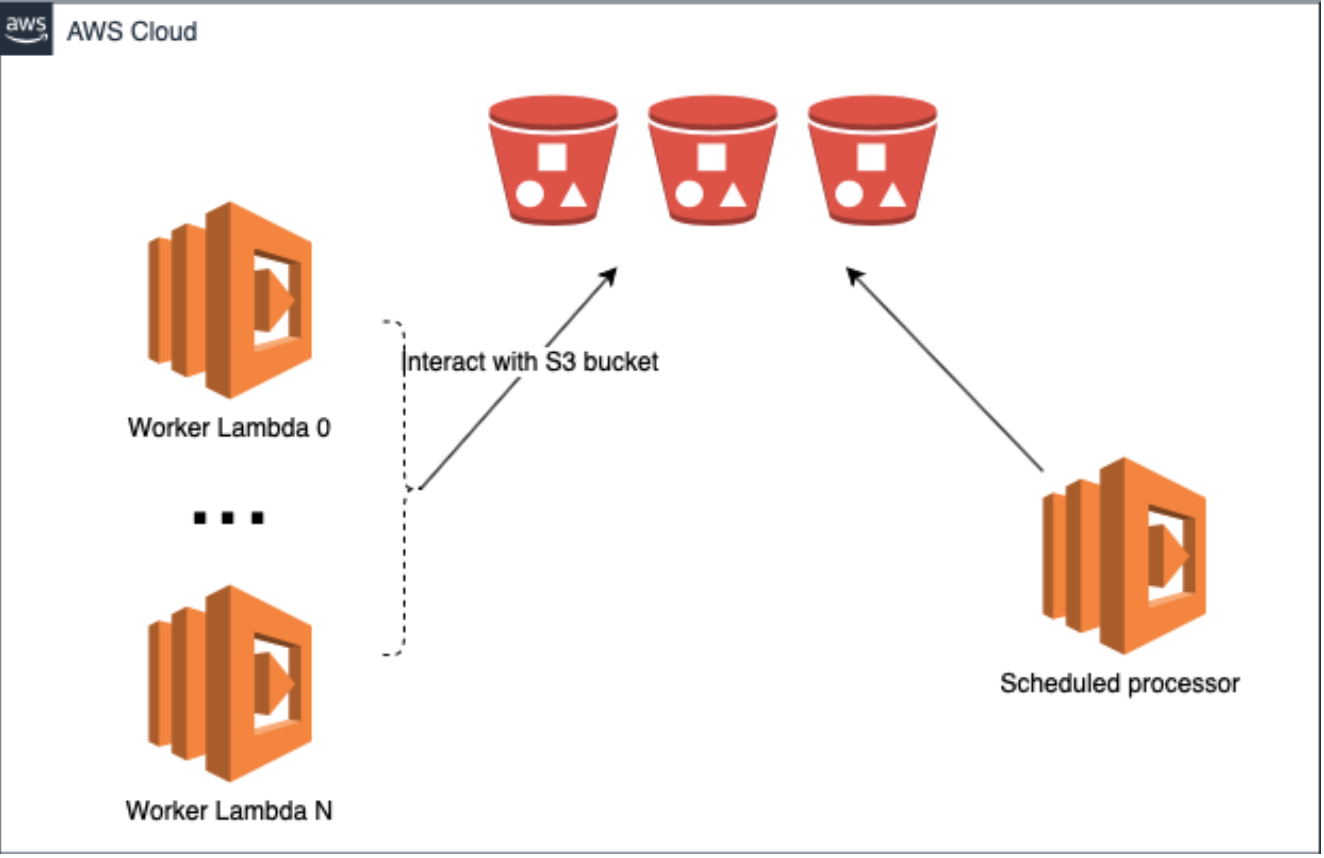
It is challenging to easily define which buckets are ready for processing. We want to have a solution where a system does not need to maintain a hard-coded ARNs of the buckets constantly, can dynamically adjust to new criteria that define buckets to be processed.
Solution
The Tag-based resource groups can serve us to define a search query and group bucket that are ready to be processed by our scheduled AWS Lambda function. Our workers would only need to tag buckets as soon as they finish with the work. So our final design is slightly changed:
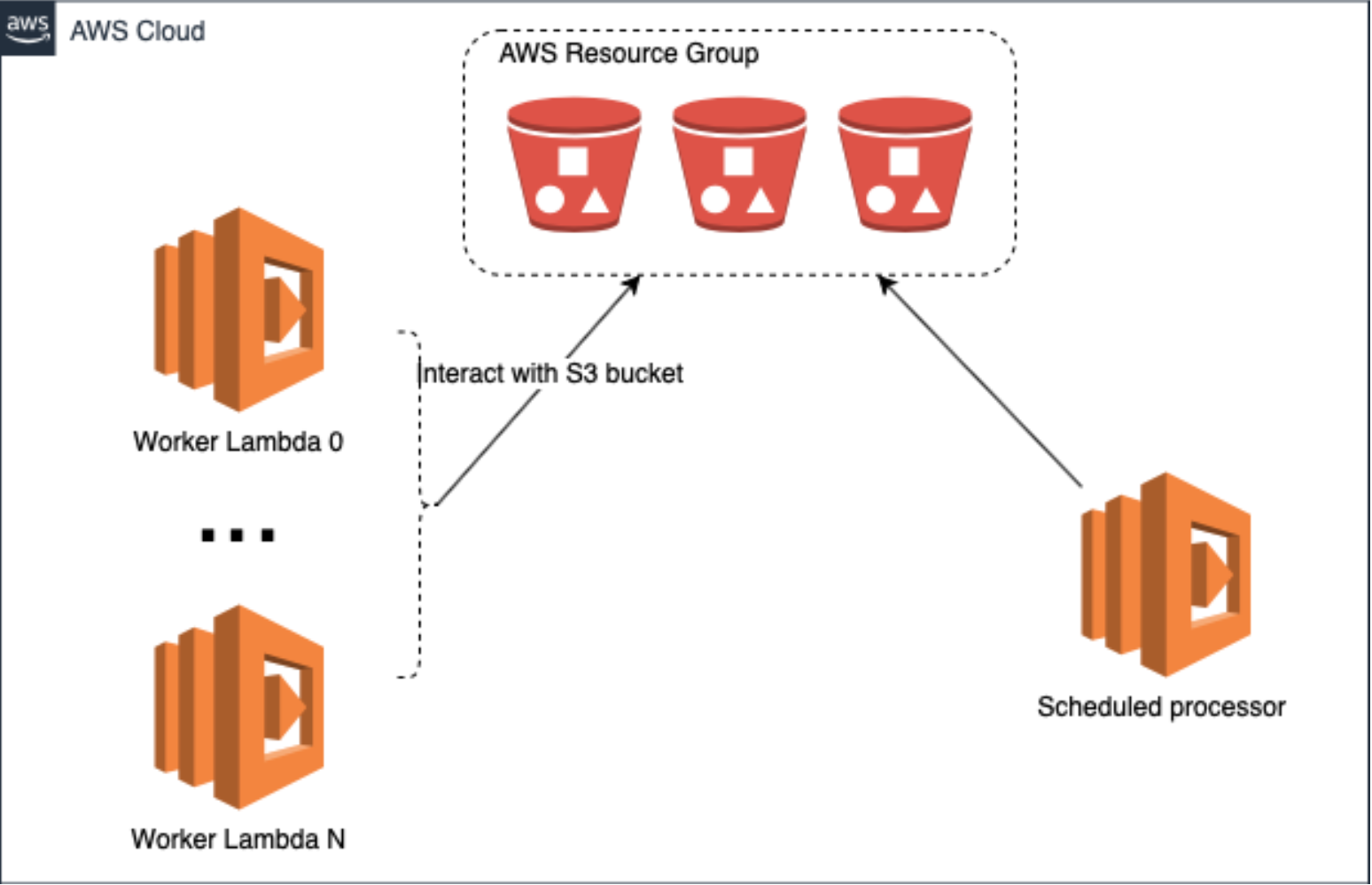
Let's see how we can implement this solution. Let's create a group with AWS CLI:
aws resource-groups create-group --name buckets-ready --resource-query '{"Type":"TAG_FILTERS_1_0","Query":"{\"ResourceTypeFilters\": [\"AWS::S3::Bucket\"],\"TagFilters\":[{\"Key\":\"status\",\"Values\":[\"ready\"]}]}"}'
This group will contains only Amazon S3 bucket that have been tag with the tag "status:ready". Now we can adjust our AWS Lambda workers to tag our S3 buckets. We are going to use Go and AWS Go SDK in this example but same can be achieved with any language supported by AWS Lambda.
func finalizeBucket(bucket string) error {
svc := s3.New(session.New())
input := &s3.PutBucketTaggingInput{
Bucket: aws.String(bucket),
Tagging: &s3.Tagging{
TagSet: []*s3.Tag{
{
Key: aws.String("status"),
Value: aws.String("ready"),
},
},
},
}
result, err := svc.PutBucketTagging(input)
if err != nil {
if castedAWSError, ok := err.(awserr.Error); ok {
switch castedAWSError.Code() {
default:
fmt.Println(castedAWSError.Error())
}
} else {
fmt.Println(err.Error())
}
return err
}
fmt.Printf("Finalized bucket %s, result: %s", bucket, result.GoString())
return nil
}
After these adjustments, our AWS Lambda workers tag bucket with the specified tag, so it means we can extend our processor to list group resources and perform an action on these resources.
func listBucketsForProcessing() ([]string, error) {
region := os.Getenv("Region")
// Get group name that holds the buckets
groupName := os.Getenv("GroupName")
config := aws.Config{Region: aws.String(region)}
newSession := session.Must(session.NewSessionWithOptions(session.Options{
Config: config,
SharedConfigState: session.SharedConfigEnable,
}))
// Create AWS Resource Groups client
client := resourcegroups.New(newSession, &config)
// Prepare request input
listGroupResourcesInput := &resourcegroups.ListGroupResourcesInput{
GroupName: aws.String(groupName),
}
listGroupResourcesResponse, err := client.ListGroupResources(listGroupResourcesInput)
if err != nil {
fmt.Println("Failed to list group resources", err)
return nil, err
}
// Process all buckets
var bucketArns []string
for _, resourceIdentifier := range listGroupResourcesResponse.ResourceIdentifiers {
processBucket(*resourceIdentifier.ResourceArn)
bucketArns = append(bucketArns, *resourceIdentifier.ResourceArn)
}
fmt.Printf("Processed %d buckets ", len(bucketArns))
return bucketArns, nil
}
Conclusion
We learned how to use AWS Resource Groups as a container in your serverless workflows. We went through a design of a simple solution for the problem that required the scheduled processing of Amazon S3 buckets. You can learn more about tagging in AWS here.